It’s been a while since I setup a new system, and although I had to look into decrypting a drive remotely a few months back when one of my servers refused the key, it’s pretty much been just as long since I really had to setup remote decryption from scratch.
Tonight I’m building up a new system to replace an existing server. The reason is it’s undergone several major distribution updates without a full reinstall and I think it starts getting messy after a while. Put that together with X refusing to startup and display my cctv stuff after updates a few months back (see other post), I really think it’s time for a clean server.
I’m not going to run through all the step for my install here, it’s pretty common Ubuntu 12.04 Alternative CD, Encrypted root, swap and data running on LVM and a /boot that’s the first partition on the disk.
Now I’ve got my system up and running, I want to be able to remotely access it while it’s booting to provide the decryption key and then let it continue. I do this on all my system, and although I’m sure you don’t need all the commands when it’s booting I use them just to be sure.
I’m making the following assumptions, you will need to adjust accordingly:-
Your machine is already on your network.
You have SSH access to your machine.
You have root privileges.
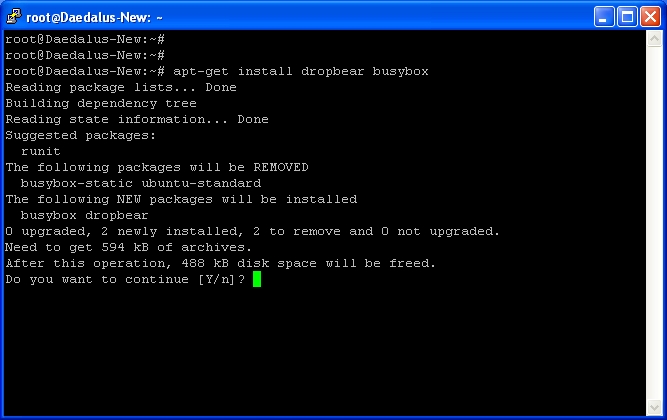
First thing is to install dropbear and busybox
apt-get install dropbear busybox
It says above it’s going to remove busybox-static and ubuntu-standard, I personally dont have any issues with this, but you may wish to search google for what these packages do (or any packages your system says it’s removing) before you continue.
At this point I reboot my system (you wont have any remote access yet), purely because I’d already run updates and forgotten to reboot before I started this blog.
When the system was rebooting, pressing escape when being prompted for the decryption password showed me the interface configuration.
I was able to make an SSH connection to the dropbear server, but unable to authenticate. Also as this was a DHCP ip address, it’s not really much good as a remote recovery system.
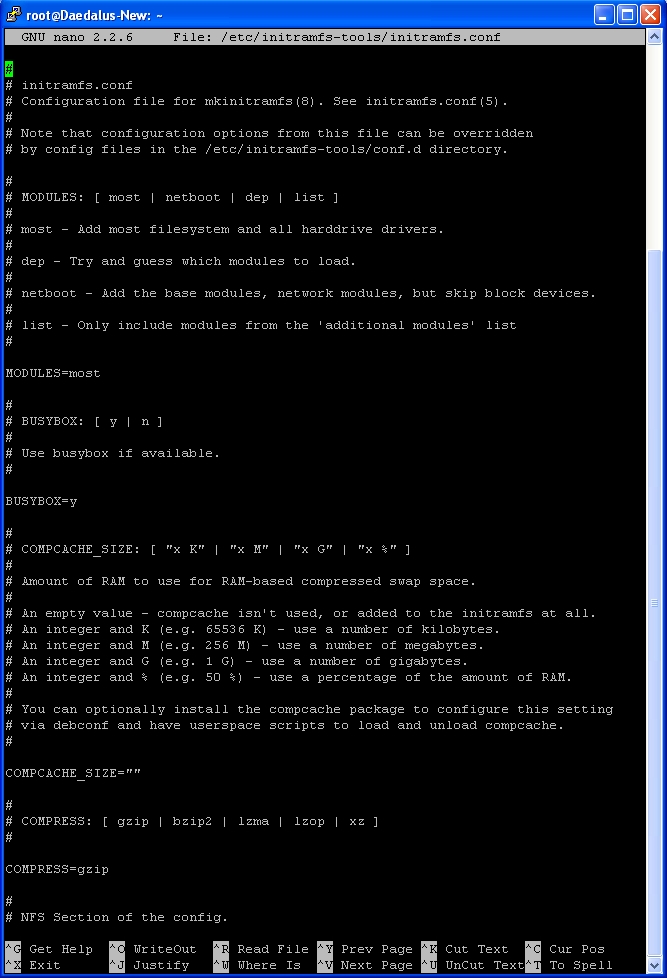
Next we need to edit initramfs.conf
nano -w /etc/initramfs-tools/initramfs.conf
Here’s how my file looks before editing:-
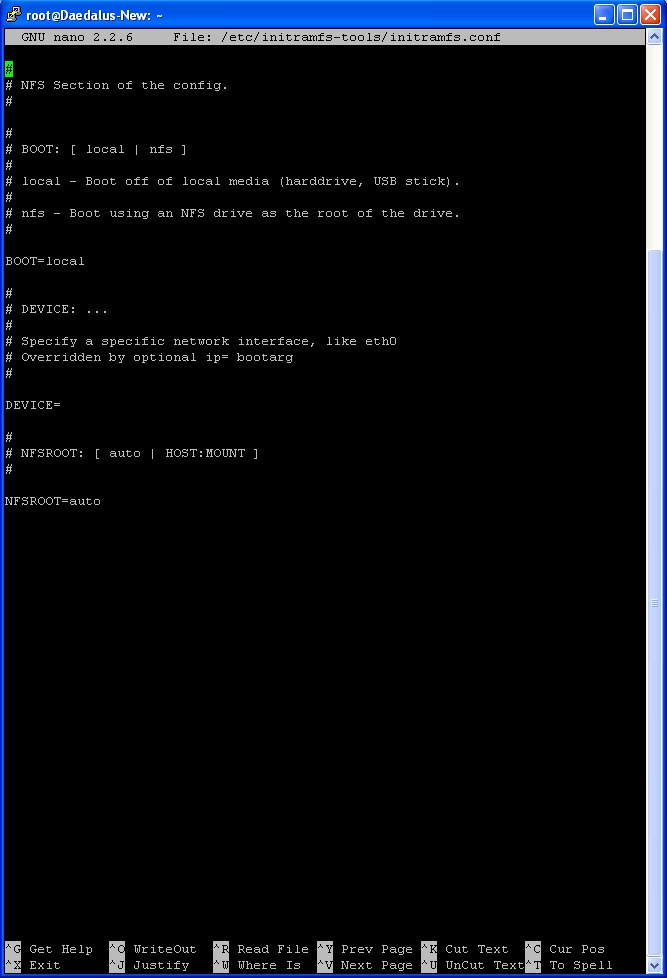
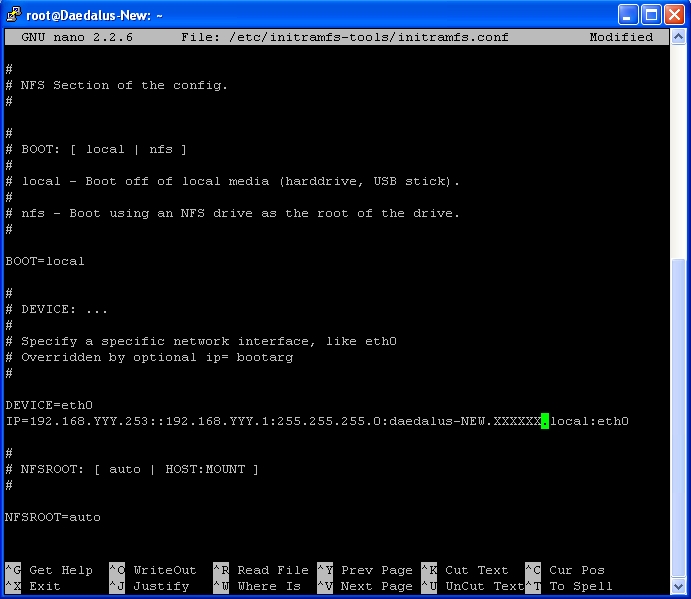
Locate the line DEVICE=
and adjust to be DEVICE=eth0
then add a line IP=192.168.yyy.253::192.168.yyy.1:255.255.255.0:daedalus.xxxxxxxxxx.local:eth0
Replacing the yyy with your own network value and xxxxxxx with your own domain
The IP= is separated into the following options IP ADDRESS :: GATEWAY : SUBNET : COMPUTERNAME : INTERFACE
There’s an option between IP and GATEWAY, {review} I need to add in explanation for but wont affect anything left empty.
Personally I use the address .253 as it’s outside my DHCP scope and not an address I’m using. I also have it setup on my router to forward SSH traffic to the .253 IP. Once the machine has boot it drops the .253 address so is only accessible externally while booting.
Save and Exit this file. CTRL+X. Followed by Y to save. Then ENTER to keep the same name.
Now we’re going to add an authorized key. First
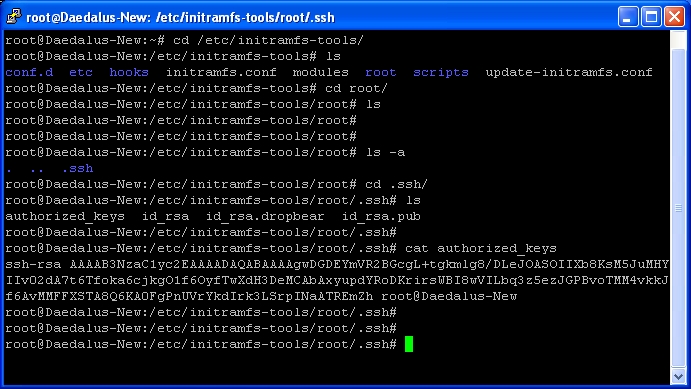
cd /etc/initramfs-tools/root/.ssh
then
cat authorized_keys
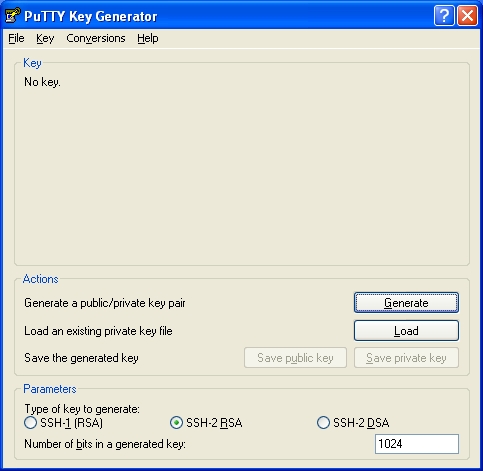
As you can see it already has an entry from the dropbear installation. However we’re going to replace this with a new key. First we must generate the key. On your windows machine open PuttyGen from your start menu:-
Press the Generate button (I increased the bits to 2048 first).
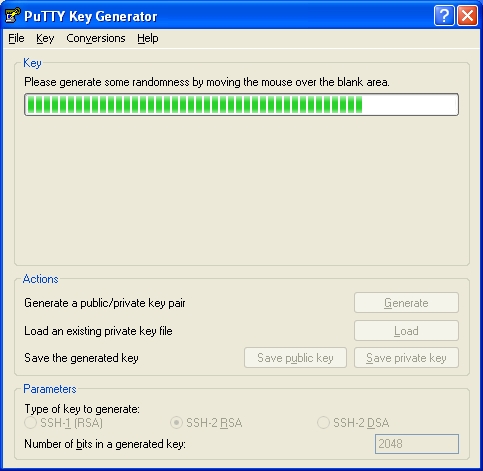
You will be asked to move the mouse randomly over the blank area until the green bar completes.
Then a key is generated:-
Once your key generation has complete, save the public key. How you choose to secure this is upto you, personally I just keep it saved in my documents, it’s not decrypting the hard drive just getting me access to do so.
With that saved right click the public key and Select All, then Copy.
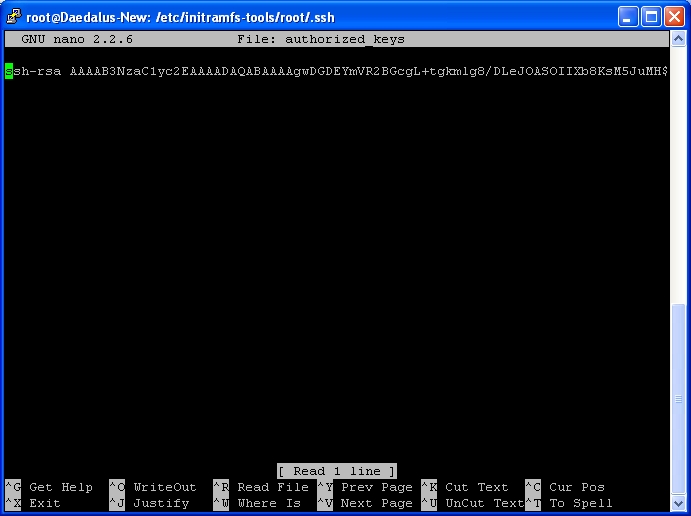
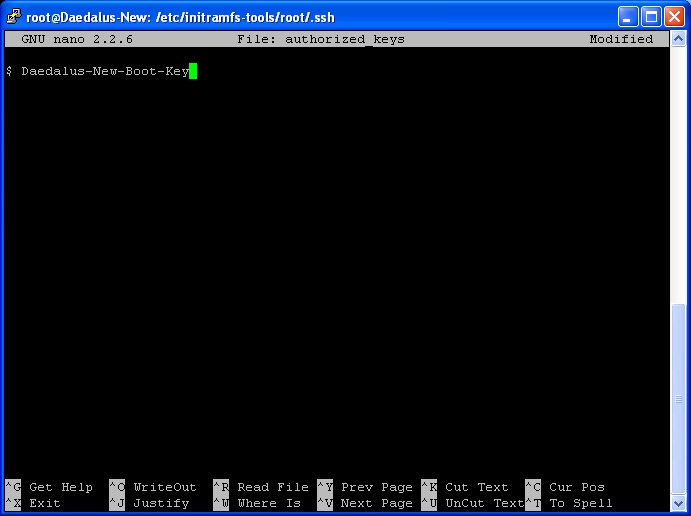
Now go back to your Putty SSH connection window and nano -w authorized_keys
As you can see the existing key is already in place. You can delete this line entire if you wish CTRL+K. If you didn’t delete just move to the next line. Once on a free line simply right click to Paste.
As you can see Nano has scrolled to the end of my line, so I can only see the Key comment. You can now Save and Exit this file. CTRL+X. Followed by Y to save. Then ENTER to keep the same name.
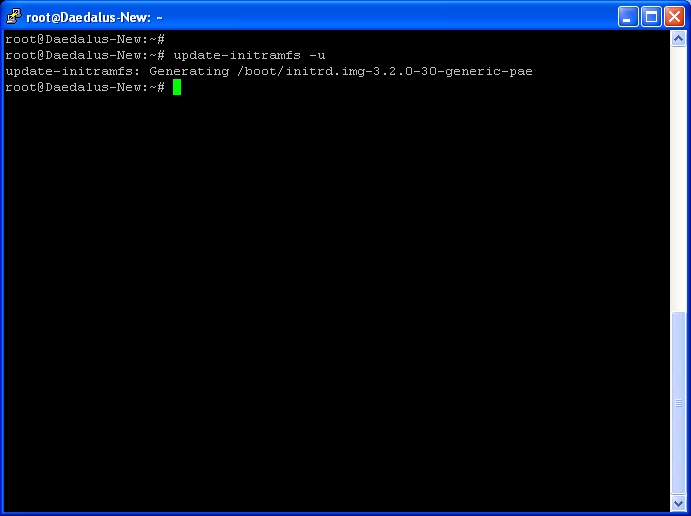
Now that we’ve made adjustments to the boot configuration you need to rebuild the boot files.
Type update-initramfs -u
UPDATE:- you may encounter the error “cp: cannot stat `/lib/x86_64-linux-gnu/libnss_*’: No such file or directory” I cover this in another post http://blog.starbyte.co.uk/cp-cannot-stat-liblibnss_-no-such-file-or-directory/
Once complete you can reboot your system ready to test.
When you system is rebooting and sat prompting for the password, press the Esc key and ensure that the network configuration is correct.
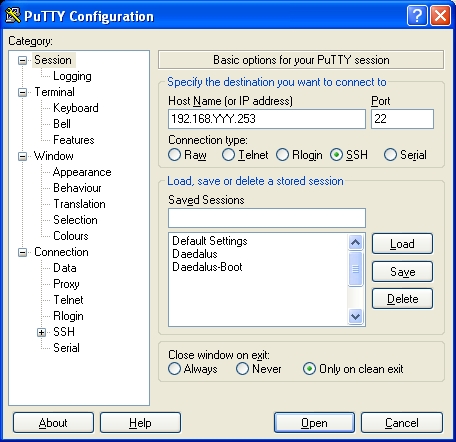
Now we need to connect to the system from our windows machine. Open Putty and start a new connection:-
Click on Data on the left hand side:-
Fill in the Auto-login username as ‘root’. Then expand SSH and select Auth:-
Browse to the private key you saved earlier.
You can either press Open to connect now, or return to the Session screen and Save the session for easy access later (I didn’t).
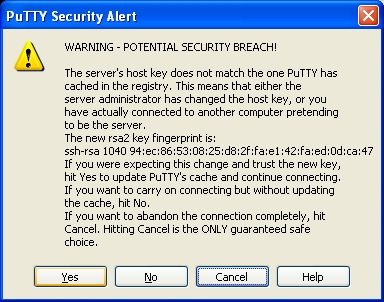
Once connecting you should be prompted to accept the fingerprint:-
You should now be connected to your server:-
You may wish to use the above to create new keys from each machine you may connect from (Desktop, Leptop, etc) and append them to the authorized_keys file. If one of your systems is then lost you can merely remove the key and regenerate the initramfs.
Now that we have our connection, we need to supply the password. Over the last few years I’ve come across various different methods. Some pipping the password into a hook, others killing the script currently asking for the password and manually unlocking the drive. The later method is the one I’ve always used, mainly because I have multiple encrypted drives and unlock each of them manually.
{sidenote: rebooting from within busybox did restart the machine, but left it on the grub selection screen no countdown. Encountered a halted boot before but didn’t know why. Need to ensure grub always has default countdown}
I’ve just run through a few quick tests of simply pipping the password and it still doesn’t work for me. So here goes with the 2nd longer process. I’d like to thank whoever I originally found this from, but I have no idea. Their steps were extremely well written (unlike mine).
First we need to stop the current script running looking for the password:-
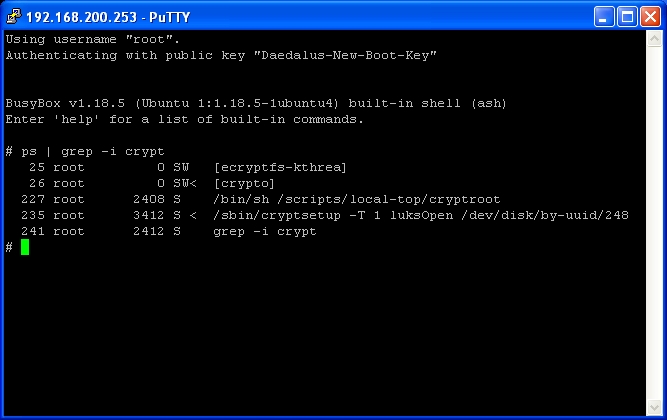
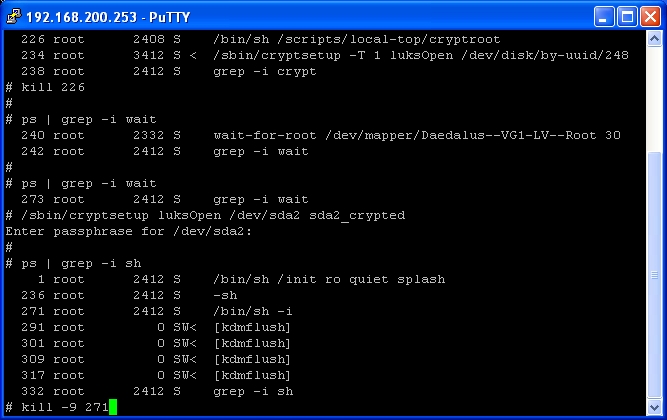
Type ps | grep -i crypt
This will list the running crypt processes. We’re interested in the script in local-top. It’s process number is 227, so we issue : kill 227
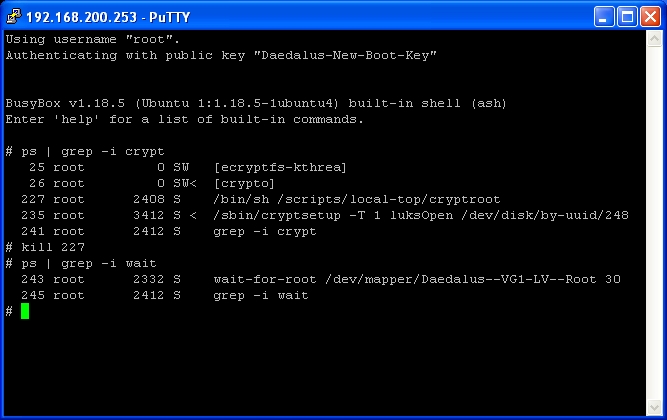
Now that we’ve issued the kill, we need to wait a while for the system to drop to a prompt. Type ps | grep -i wait
As above you will see the wait-for-root script running, and it has a value of 30 (meaning 30 seconds). If you wait 30 seconds and rerun ps | grep -i wait, you will find it’s no longer running.
You can now continue to unlock your drive(s)
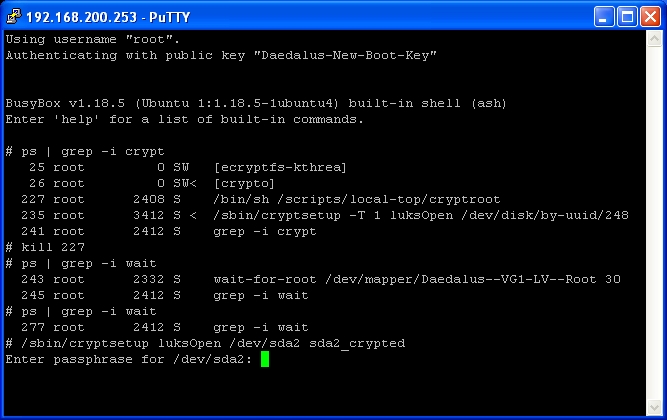
In the image above you can see where wait-for-root was running, then the following check it wasn’t. Followed by the command I use to unlock my drive.
Type /sbin/cryptsetup luksOpen /dev/zzzz zzzz_crypted
Replacing the zzzz with your drive and partition. If your unsure you can always double tab for suggestions.
You wont get any password feedback, so if you think you’ve made a mistake hold the backspace key for a while then type again.
If your password is accepted you will be returned to a prompt.
At this stage we tell the shell to kill itself:-
Use ps | grep -i sh to find the process number (271in the above) then kill -9 271
Follow by exit
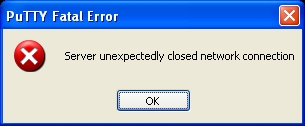
If all has gone well I normally receive:-
Normally if I haven;t received this, I’ve done something wrong. At which point physical access is required to correct my mistake (or get someone to reset the machine and try again).
At some point I may make a script or 2 to run and see if it hasn’t been unlocked within 30 mins to reset. This may give me a bit of resilience is screwing it up. After a few times of unlocking though you really do remember the commands. I did save a text file into the root folder /etc/initramfs/root/guide.txt
(Thinking of that now I’ll just paste that below – again thanks to whoever originally wrote it. but after a few times I didn’t need it anymore.)
1) run “ps aux” and located the process id for the /scripts/local-top/cryptroot script
2) run “kill -9 pid” replacing pid with the process id you found in step 1
3) run “ps aux” again and look for a wait-for-root script and note the timeout on the command line
4) twiddle you thumbs for that many seconds – what will happen is that script will exit and start an initramfs shell
5) run “/scripts/local-top/cryptroot” and wait for it to prompt for your unlock passphrase
6) enter the unlock passphrase and wait for it to return you to the busybox shell prompt
6.5) Unlock each drive to get a clean boot, sda,sdb,sdc,sdd as sda_crypt,sdb_crypt,sdc_crypt,sdd_crypt
7) run “ps aux” again and locate the process id of “/bin/sh -i”
8) run “kill -9 pid” using the process id you found from step 7
As you can see I added 6.5 to remind me to decrypt other drives. Doing this means their mounted as the system is coming up.
That’s pretty much it. You should now be able to remotely unlock your encrypted drives.I realised towards the end my internal IP is on the top of the putty windows, but I only really masked it from the examples to highlight a change. I hope people find this somewhat helpful. Any feedback welcome, I’m now off to start copying data over. and btw I’ve changed the keys incase anyone worries for me 🙂
UPDATE:-
I’m just running through this on 12.10 and ran into a problem whereby the ip address yyy.253 wasn’t being released. Some searching suggested that network/interfaces will be ignored because of checks in the process that fail. This wasn;t the case for me, I was getting 2 addresses on the interface. The solution was to add:-
pre-up ip addr flush dev eth0
To /etc/network/interface to clear eth0 before applying the new IP.