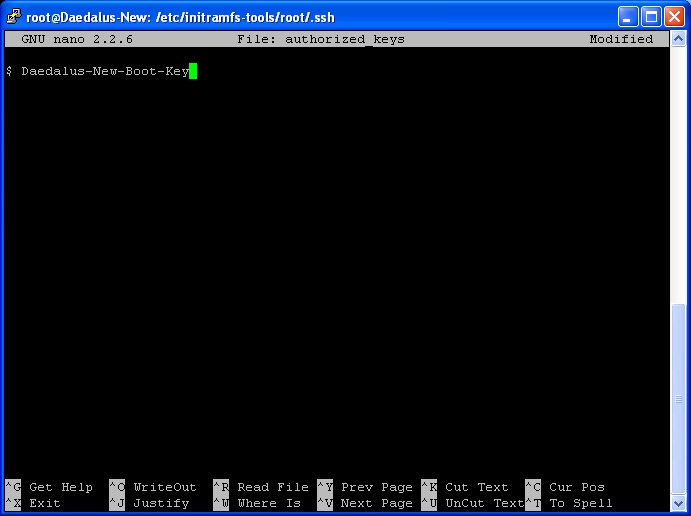
I’ve had nagios running for years, so decided to play around with the alerts.
Twitter seemed the obvious choice, it’s easy for a people to follow the twitter account that’s publishing the alerts, and great if you actively use twitter (I don’t, this was more of a ‘how would you’ rather than a need).
First thing is to register a twitter account that nagios will publish as. I setup https://twitter.com/NagiosStarB
Once you’ve registered you need to edit your profile and add a mobile phone number (This is needed before you can change the app permissions later. Once you’ve done that you can delete the mobile number).
Now head over to https://apps.twitter.com/ and create a new app
Fill in Name, Description and Website (This isn’t particularly important, as we’re not pushing this app out to users).
You’ll be taken straight into the new app (if not simply click on it).
We need to change the Access Level, Click on ‘modify app permissions’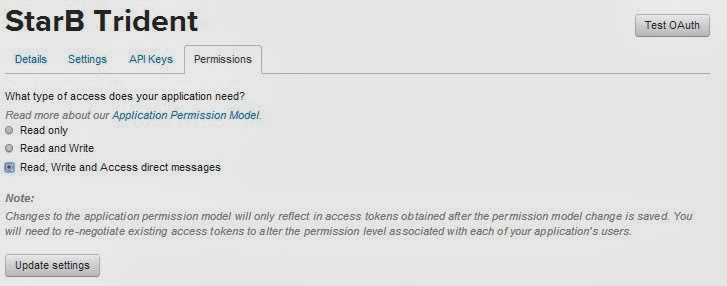
I chose ‘Read, Write and Access direct messages’, although ‘Read and Write’ would be fine. Click ‘Update settings’ (If you didn’t add your mobile number to your account earlier, you;ll get an error).
Now click ‘API Keys’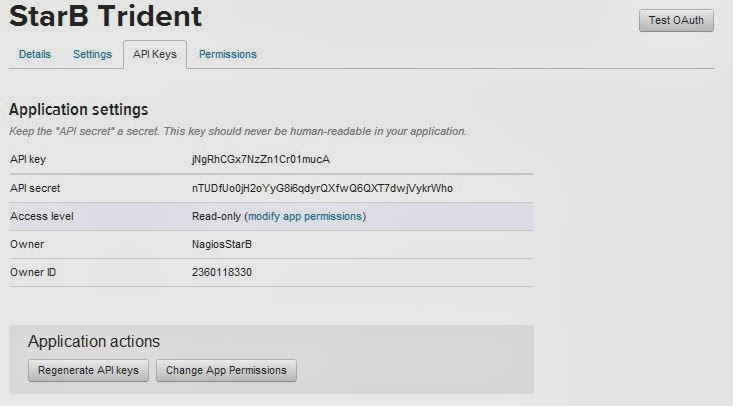
You need to copy the API key and API secret (Please dont try to use mine).
Now click ‘create my access token’ close to the bottom of the page.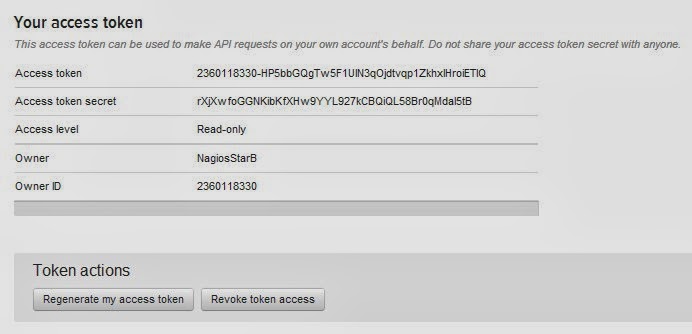
You also need to copy your ‘Access token’ and ‘Access tocken secret’
Now we move onto the notification script.
Login to your Nagios server via SSH.
You need to ensure you have python-dev & python-pip installed.
apt-get install python-dev python-pip
pip install tweepy
Then cd into your nagios libexec folder (mines at /usr/local/nagios/libexec)
cd /usr/local/nagios/libexec/
We now add a new file called twitternagiosstatus.py
nano -w twitternagiosstatus.py
Copy and paste the following code into the file
#!/usr/bin/env python2.7
# tweet.py by Alex Eames http://raspi.tv/?p=5908
import tweepy
import sys
import logging
# Setup Debug Logging
logging.basicConfig(filename='/tmp/twitternagios.log',level=logging.DEBUG)
logging.debug('Starting Debug Log')
# Consumer keys and access tokens, used for OAuth
consumer_key = 'jNgRhCGx7NzZn1Cr01mucA'
consumer_secret = 'nTUDfUo0jH2oYyG8i6qdyrQXfwQ6QXT7dwjVykrWho'
access_token = '2360118330-HP5bbGQgTw5F1UIN3qOjdtvqp1ZkhxlHroiETIQ'
access_token_secret = 'rXjXwfoGGNKibKfXHw9YYL927kCBQiQL58Br0qMdaI5tB'
# OAuth process, using the keys and tokens
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
# Creation of the actual interface, using authentication
api = tweepy.API(auth)
if len(sys.argv) >= 2:
tweet_text = sys.argv[1]
logging.debug('Argument #1 ' + tweet_text)
if len(tweet_text) <= 140:
logging.debug('Tweeting: ' + tweet_text)
api.update_status(tweet_text)
else:
print "tweet sent truncated. Too long. 140 chars Max."
logging.debug('Too Long. Tweet sent truncated.')
api.update_status(tweet_text[0:140])
Replace consumer_key with your API key, consumer_secret with your API secret, access_token with your access token and access_token_secret with your Access token secret.
Now save and exit the editor.
CTRL+x then Y then Enter.
With the file saved, we need to make it executable.
chmod +x twitternagiosstatus.py
You can now test that the script works by typing
./twitternagiosstatus.py "testy testy"
You should now be able to see the Tweet on your new account (you may need to refresh the page).
If all has gone well so far, you can now add your Nagios Configuration.
Change Directory into your nagios etc
cd /usr/local/nagios/etc/
Edit your commands.cfg (mine is inside objects)
nano -w objects/commands.cfg
Where you choose to place the new configurations doesn’t really matter, but to keep things in order I choose just below the email commands.
Copy and paste the following
# 'notify-host-by-twitter' command definition
define command{
command_name notify-host-by-twitter
command_line /usr/local/nagios/libexec/twitternagiosstatus.py "$NOTIFICATIONTYPE$: $HOSTALIAS$ is $HOSTSTATE$"
}
# 'notify-service-by-twitter' command definition
define command{
command_name notify-service-by-twitter
command_line /usr/local/nagios/libexec/twitternagiosstatus.py "$NOTIFICATIONTYPE$: $SERVICEDESC$ ON $HOSTALIAS$ is $SERVICESTATE$"
}
You can adjust the specifics, but adding other $$ arguments (Use the email notification commands as an example). Save and exit
CTRL+x, then Y, then ENTER
Now we add a new contact. Edit contacts.cfg
nano -w objects/contacts.cfg
Copy and Paste the following
define contact{
contact_name nagios-twitter
alias Nagios Twitter
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r,f
host_notification_options d,u,r,f,s
service_notification_commands notify-service-by-twitter
host_notification_commands notify-host-by-twitter
}
define contactgroup{
contactgroup_name nagiostwitter
alias Nagios Twitter Notifications
members nagios-twitter
}
I decided to create a specific contact and contact-group for this, but you can adjust as you wish, add the contact to other contact-groups if you wish.
Now the last bit,
Add the new contact group to the hosts & services, templates or host-groups and service-groups.
How you decide to do this will depend on how you’ve set out your hosts, services, templates and contacts. For me I edit the each of the host files and add contact_groups nagiostwitter to each host and service.
(IMPORTANT: this will override settings that are inherited from templates, so if you already have email notifications active you’ll either have to just add nagiostwitter to the template or add users to this). Dont forgot to , delimited
An example host of mine
define host{
use linux-server ; Name of host template$
; This host definition $
; in (or inherited by) $
host_name excalibur
alias Excalibur
address 192.168.1.27
parents switch-netgear8
hostgroups linux-servers
statusmap_image linux40.gd2
contact_groups nagiostwitter,sysadm
}
An example service on this host
define service{
use generic-service ; Name of servi$
host_name excalibur
service_description PING
check_command check_ping!100.0,20%!500.0,60%
contact_groups nagiostwitter,sysadm
}
That’s it, hopefully if all’s done right you can restart the nagios service.
/etc/init.d/nagios restart
Now your twitter feed will start to be populated with each alert. I can’t emphasis enough that if the nagios configuration is done wrong you may break other alerts that are already setup.
I really need to thank http://raspi.tv/2013/how-to-create-a-twitter-app-on-the-raspberry-pi-with-python-tweepy-part-1#install here as I used this as a starting point.
UPDATE:
A few weeks ago I received an email from twitter telling me my application had been blocked for write operations. It also said to check the Twitter API Terms of Service. I didn’t think this would cause a problem, I’m not spamming anyone other than myself or users I’ve asked to follow the alerts. So I read the Terms of Service, and it’s all fine. I raised a support request with Twitter and had a very quick response saying “Twitter has automated systems that find and disable abusive API keys in bulk. Unfortunately, it looks like your application got caught up in one of these spam groups by mistake. We have reactivated the API key and we apologize for the inconvenience.”
This did stop my alerts for a few days though.So just be aware of this.
UPDATE 2:
Thanks to a comment from Claudio to truncate messages over 140 characters. I’ve incorporated this recommendation into the code above.